🔴 The Problem
Preference labels in alignment data are often noisy and inconsistent, but many methods assume uniform reliability.
Preference labels in alignment data are often noisy and inconsistent, but many methods assume uniform reliability.
We introduce an EM-style reliability-aware weighting mechanism for adaptive loss reweighting during optimization.
Across Mistral-7B and Llama-3-8B, RE-PO improves AlpacaEval 2 LC and WR over DPO baselines.
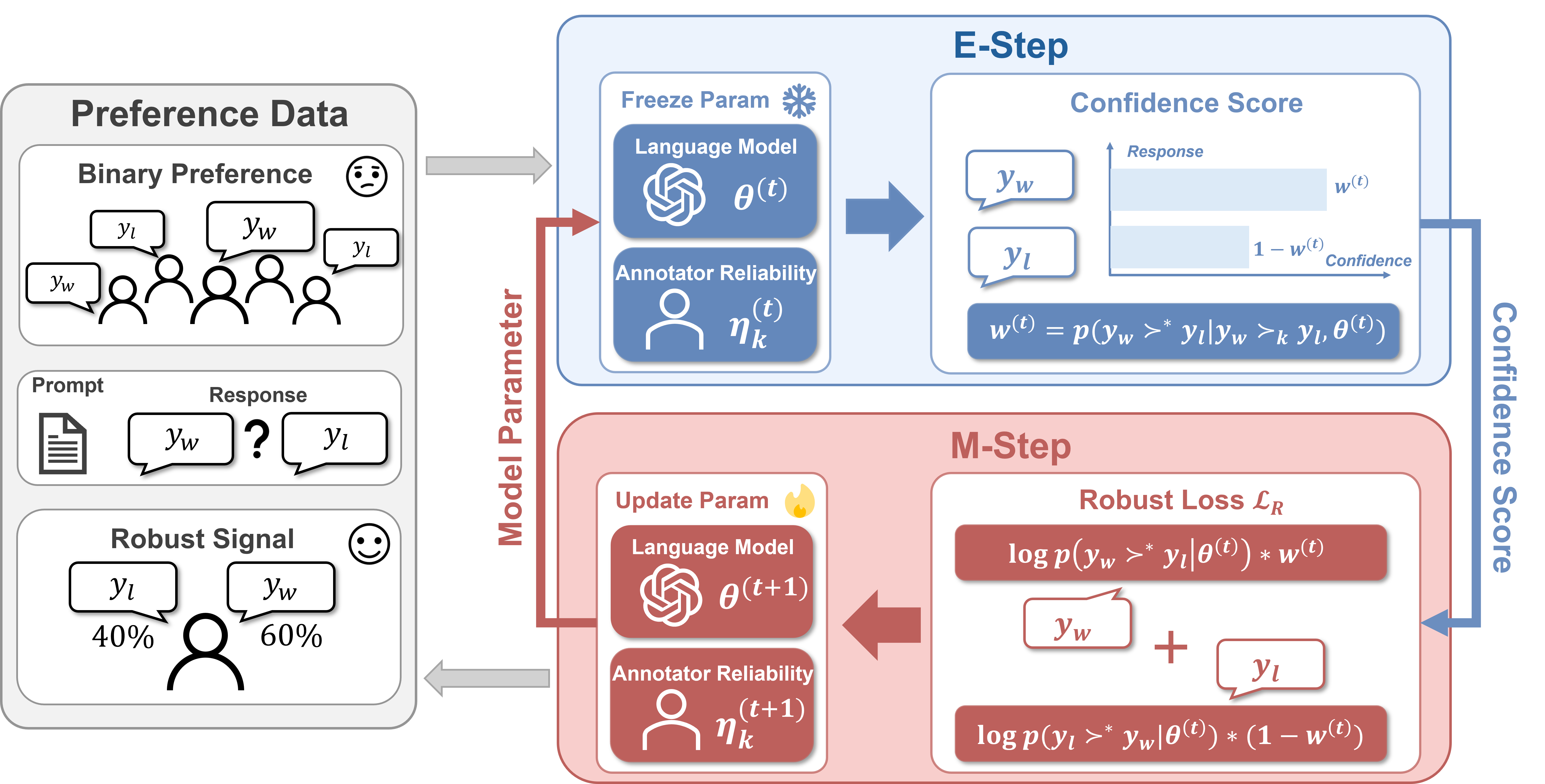
RE-PO models observed preferences as potentially noisy signals. In the E-step, it estimates posterior confidence that each label is correct. In the M-step, it updates policy parameters and annotator reliability with these confidences as weights.
This keeps the training pipeline close to DPO while improving robustness against corrupted or inconsistent feedback.
Across DPO, IPO, SimPO, and CPO families, RE-PO generally improves LC and WR on UltraFeedback, and RE-DPO remains stronger than DPO on MultiPref.
| Dataset | Model | Method | Standard (LC/WR) | RE-PO (LC/WR) | Delta LC | Delta WR |
|---|
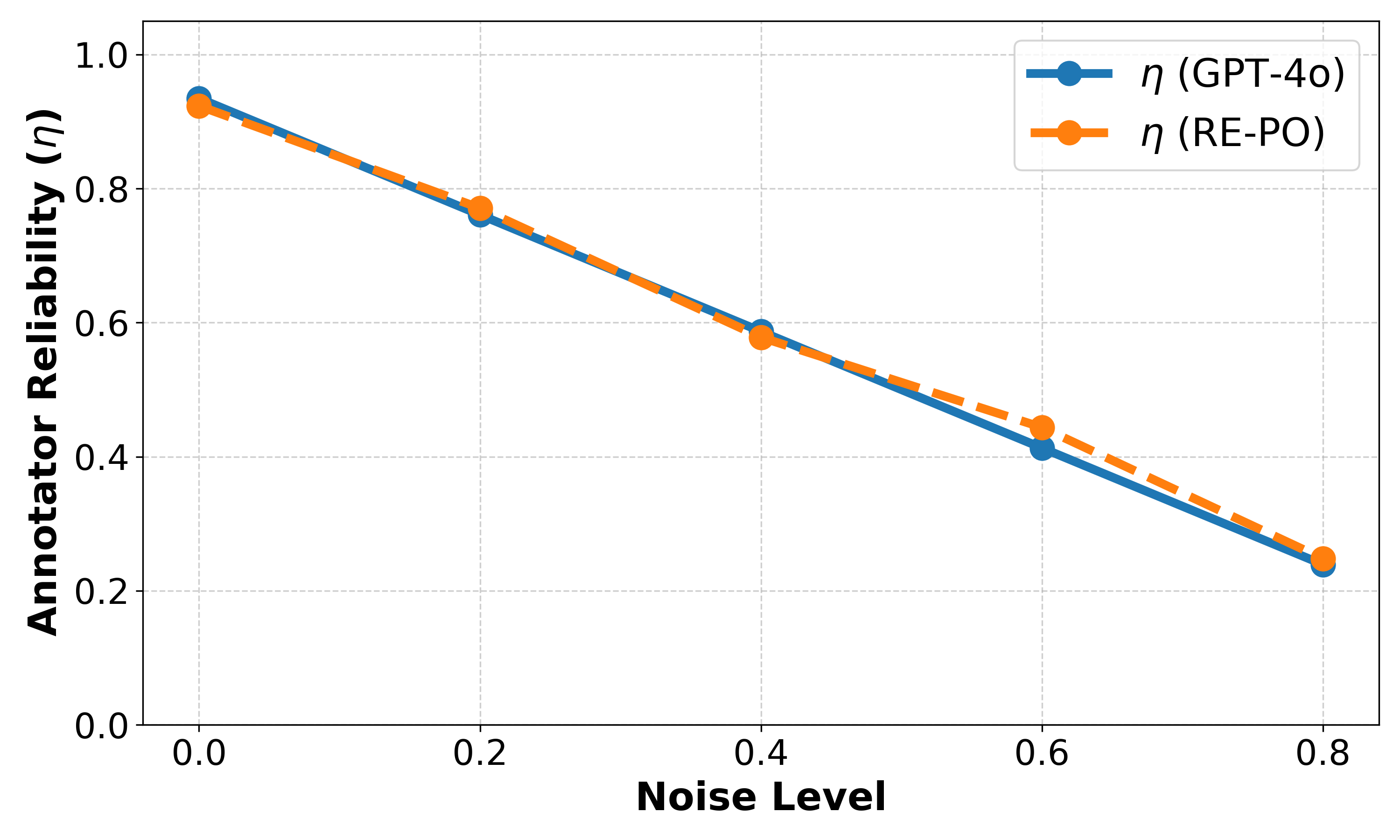
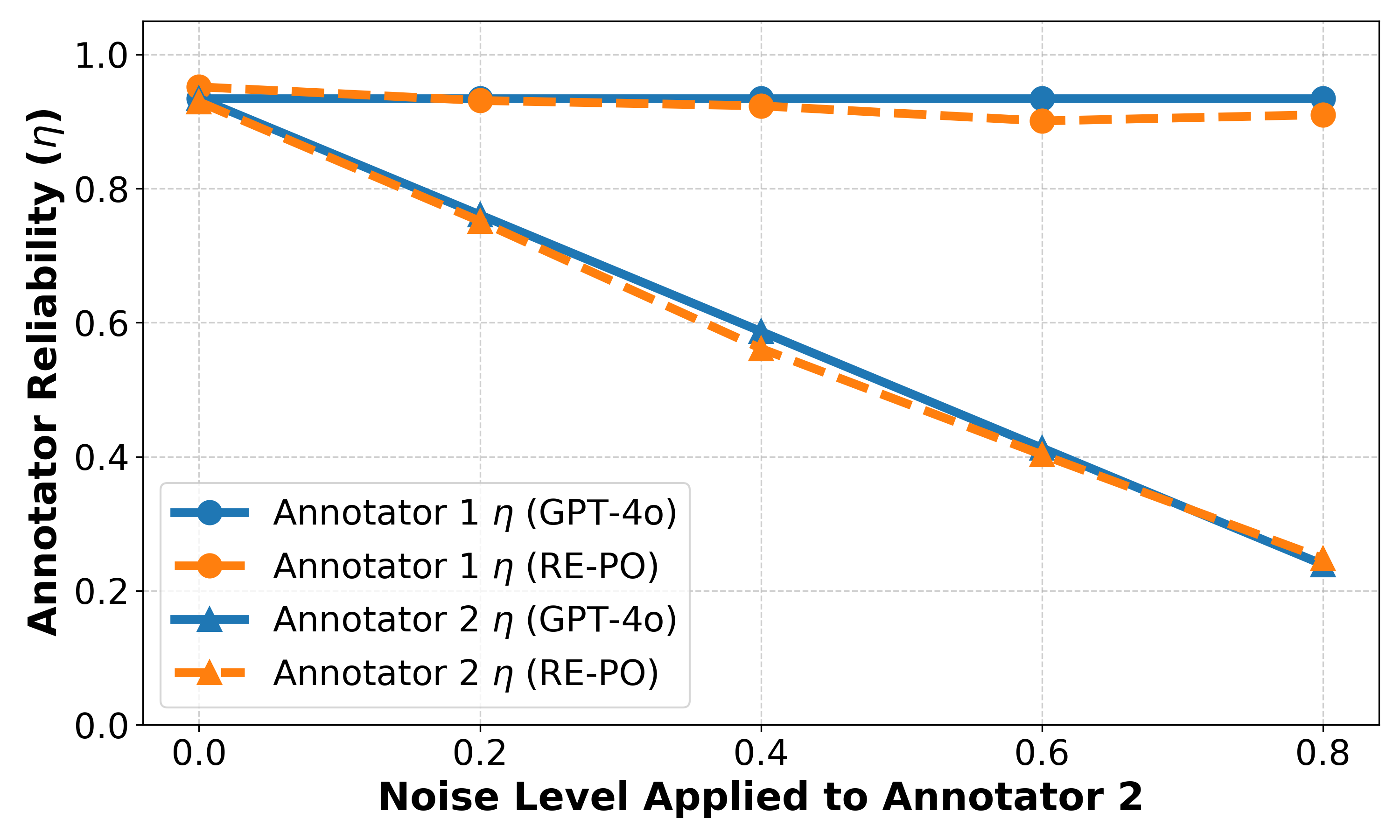
RE-PO estimated reliabilities track ground-truth trends under synthetic noise in both single-annotator and two-annotator settings.
If RE-PO is useful to your research, please cite:
@inproceedings{cao2026repo,
title = {RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment},
author = {Cao, Xiaoyang and Xu, Zelai and Guang, Mo and Long, Kaiwen and Bakker, Michiel A. and Wang, Yu and Yu, Chao},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2026}
}